
In een wereld vol AI hebben media met hun archief goud in handen

In deze nieuwsbrief wil ik het met je hebben over:
- Mediabedrijven moeten hun archief klaarmaken om eigen AI-modellen te trainen.
- Jongeren laten betalen voor je missie? Leer van makers en communiceer je missie.
Mediabedrijven moeten hun archief klaarmaken om eigen AI-modellen te trainen
De BBC maakt plannen om zelf AI-modellen te ontwikkelen op basis van zijn archief. Dat schrijft de Financial Times. Daarnaast zou de Britse publieke omroep overwegen om licentiedeals te sluiten met techbedrijven zodat het archief van de omroep gebruikt kan worden om hun modellen te trainen. De BBC zou onder meer in gesprek zijn met Amazon.
Toen ik dit las, moest ik meteen denken aan een presentatie van de CTO van Paramount Global, Phil Wiser. Hij vertelde uitgebreid over hoe het entertainmentbedrijf aan het experimenteren is met het ontwikkelen van eigen AI-modellen op basis van archiefcontent van specifieke franchises. Zo heeft het, op basis van Adobe Firefly, een zogeheten custom model voor Spongebob Squarepants ontwikkeld. Dit model is getraind op het archief aan beeldmateriaal van de populaire tekenfilmserie, waardoor daarmee nieuwe afbeeldingen van Spongebob Squarepants kunnen worden gereageerd die niet onderdoen voor het origineel. Dat terwijl bij openbare/algemene modellen het bij het resultaat duidelijk te zien is dat het geen originele Spongebob-cartoon is.
Wiser zegt dat hij verwacht dat het combineren van de foundation models van de grote techbedrijven en die trainen op eigen archiefdata om een eigen custom model te ontwikkelen, de interessantste ontwikkeling is voor het gebruik van generatieve AI binnen de entertainment- en media-industrie. Uiteindelijk valt of staat daarbij alles met het archief.
Voor het trainen van het Spongebob-model kon niet zomaar Firefly worden losgelaten op het archief van de tekenfilmserie. De trainingsdata moest zijn voorzien van goede metadata en beeldmateriaal van de personages en de achtergronden (de onderwaterwereld van Spongebob) moest los van elkaar worden gebruikt om uiteindelijk tot realistische resultaten te komen.
Bij tekstarchieven zal het wat dat betreft iets makkelijker zijn om deze klaar te maken om te doen als trainingsdata, maar zeker bij beeldmateriaal kan dit nog een flinke klus zijn.
Wiser zei daarover:
We zijn heel veel bezig met ons archief. Dat is ons trainingsmateriaal, maar die data is er nu niet geschikt voor. De data moet metadata hebben en georganiseerd worden. Dat is op dit moment de grootste uitdaging voor mediabedrijven en we zijn hier echt pas net mee begonnen.
In dat opzicht ben ik benieuwd hoe dat bij de BBC zit. Hoeveel werk hebben zij nog aan hun archief voordat het geschikt is om gebruikt te worden als trainingsdata? En dus vooral: hoe snel kunnen ze daadwerkelijk aan de slag met een goed getraind custom model?
Zoals de CTO van Paremount Global: dit is op dit moment de grootste uitdaging voor mediabedrijven en ik vraag me af of iedereen hier al mee bezig is of zich hier überhaupt bewust van is. Ik vrees dat er nog een heleboel werk aan de winkel is...
Jongeren laten betalen voor je missie? Leer van makers en communiceer je missie
Het American Press Institute heeft onlangs onderzoek gedaan naar het betaalgedrag van 'jongeren' (16-40) voor nieuws. Dit onderzoek had ik al een tijdje klaar staan om te bespreken in mijn nieuwsbrief, maar ik twijfelde erover. Het is immers een Amerikaans onderzoek en het Amerikaanse medialandschap en het gedrag van het publiek zijn fundamenteel anders dan bij ons. Sowieso zie je dat de verschillen qua betalen voor nieuws internationaal sterk verschillen, zeker online. In Scandinavische landen is betalen voor nieuws op internet de normaalste zaak van de wereld, in het Verenigd Koninkrijk gebeurt het juist heel weinig. Nederland is een beetje een middenmotor en het Digital News Report van vorig jaar (pdf) laat zien dat hoe jonger de groep, hoe groter het deel van hen is dat betaalt voor nieuws op internet.
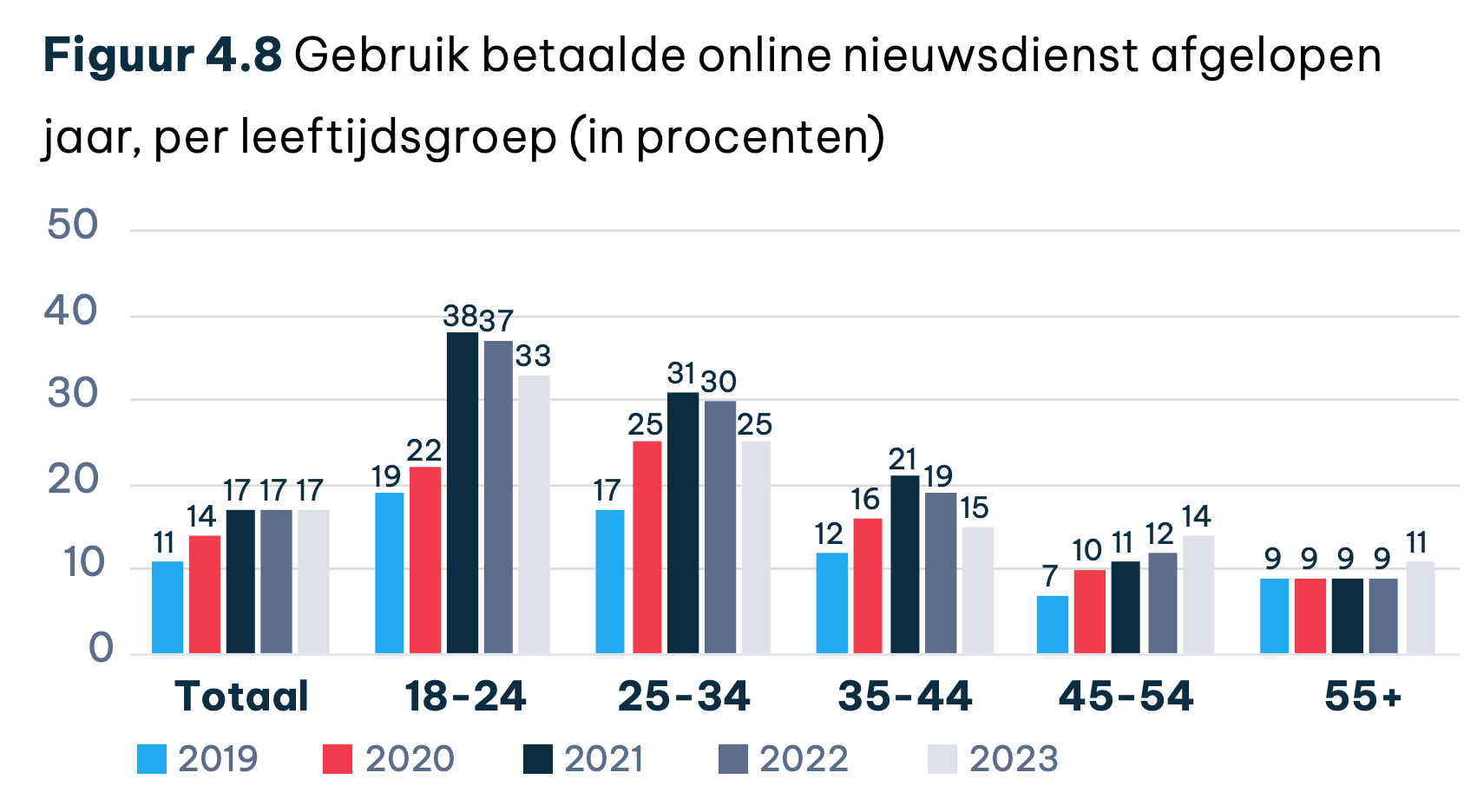
Dit gaat dus voor de duidelijkheid over het betalen voor nieuws op internet, niet nieuws in het algemeen. En daarbij geldt logischerwijs dat de oudere groepen betalen voor nieuws in printvorm, terwijl jongere groepen dat nauwelijk doen. Ik heb nog gezocht naar recente Nederlandse totaalcijfers, waarin dit samenkomt, maar die heb ik niet kunnen vinden.
Terug naar het Amerikaanse onderzoek naar het betaalgedrag van jongeren. Daarin komen namelijk een aantal lessen naar voren voor uitgevers:
- Het betrekken van Gen Z en millennials op social media moet een integraal onderdeel zijn van strategieën voor het behouden van abonnees en donateurs. Dit ondanks het feit dat het steeds belangrijker wordt voor nieuwsorganisaties om relaties op te bouwen op eigen kanalen, doordat bedrijven als Facebook steeds minder met nieuws doen. De reden is simpel: deze groepen brengen een heel groot deel van hun tijd door op social media.
- De opkomst van 'nieuwsmoeheid' betekent niet dat Generatie Z en Millennials niet bereid zijn te betalen voor nieuws. Het steunen van een missie waarin ze geloven is belangrijk voor hen. Dat maakt het essentieel voor nieuwsorganisaties om hun missie duidelijk te communiceren.
- Nieuwsmedia kunnen leren van de aantrekkingskracht en aanpak van zelfstandige makers. In de VS betalen bijna twee keer zoveel van de 'jongeren' aan onafhankelijke nieuwsbrieven of video- of audiowerk van onafhankelijke makers dan aan traditionele nieuwsmedia. De onderzoekers adviseren om in de beweegredenen hiervoor te duiken, waaronder de authenticiteit van makers die het publiek ervaart en de mogelijkheid om bijvoorbeeld ook eenmalig financieel te steunen.
Ik denk dat bijvoorbeeld een titel als De Correspondent er zeker in de beginjaren ontzettend goed in slaagde om jonge lezers te laten betalen door een combinatie van punt 2 en 3. De duidelijke missie resoneerde met een hoogopgeleide, linkse, jonge doelgroep. Daarnaast was de persoonlijke aanpak van de auteurs die schreven op De Correspondent iets dat in lijn is met de authenticiteit van zelfstandige makers.
Het Britse tijdschrift The Economist probeert al een paar jaar een jonge doelgroep aan zich te binden met de app Espresso. Voor 8 euro per maand krijgen lezers toegang tot een dagelijkse selectie verhalen van The Economist. Dat is niet alleen veel goedkoper dan een abonnement op het tijdschrift zelf, maar het is ook echt bedoeld voor een andere doelgroep met een andere behoefte.
It is sort of the bite -sized version of The Economist. It gives you the World in Brief, which is a flagship franchise within our core app as well, which gives you the most important headlines of the day with a little bit more context behind them. We update it three times a day on Espresso, and so you get a nice feed of what's really important in the world that day. It's a snack-size version if you will, but it's not in any way a diluted version. It's not a substitute to the core product. It targets a more female audience, a younger audience and a student audience .so it is fitting nicely into the audience spectrum and fulfils a different need to our core product.
Dat vertelde marketingbaas Nada Arnot onlangs in de podcast van Press Gazette. De app had vorig jaar bijna 22.000 abonnees, wat slechts 2 procent is van het totaal aantal abonnees dat The Economist heeft. Tegelijkertijd is het aantal Espresso-abonnees vorig jaar met 74 procent gegroeid ten opzichte van vorig jaar, nadat de uitgever meer investeerde in marketingactiviteiten. Er is onder meer doelgericht geprobeerd om studenten te verleiden om een abonnement op de app te nemen.
Los van het feit dat Espresso niet het daverende succes is dat The Economist voorgoed heeft veranderd, geloof ik wel dat productdifferentiatie de oplossing kan zijn om een jongere doelgroep te laten betalen voor nieuws. Dat kan in de vorm van Espresso of FT Edit, zoals de Financial Times doet, maar ook door meer in te zetten op nieuwsbrieven over specifieke onderwerpen die een jonger publiek interessant vindt, zoals NRC doet.
Kort
- Google heeft in Frankrijk een boete van 250 miljoen euro gekregen, omdat het bedrijf geen afspraken heeft gemaakt met nieuwsmedia voor het gebruik van nieuws in Google News en het zijn taalmodellen heeft getraind op de artikelen van media zonder hen te informeren.
- Het Amerikaanse zakenblad Fortune is de afgelopen jaren bezig om de investeren in de Europese markt. Het Europese team wordt dit jaar uitgebreid naar 35 medewerkers. Zij werken vanuit Londen.
- Twee grote Amerikaanse krantenuitgevers hebben hun contract met persbureau AP opgezegd.
- Wat in de VS vorig jaar al is gebeurd, gaat in Nederland in juni gebeuren: HBO Max en Discovery+ worden samengevoegd tot één streamingdienst. Nederland is het enige land waar de dienst niet van naam verandert, omdat de naam Max hier al wordt gebruikt door een publieke omroep. De nieuwe dienst wordt de plek om online de Olympische Spelen te volgen in Nederland. Het is nog niet bekend of klanten die een levenslange korting hebben op een abonnement deze behouden.
- Meta zit niet te wachten op nieuws op Threads, maar wil wel dat het dé plek wordt waar tijdens wedstrijden over sport wordt gepraat. En dus gaat de app (live) scores tonen als je naar berichten zoekt over een wedstrijd.
- Meta heeft de EU aangeboden om de prijs van een reclamevrij abonnement op Facebook of Instagram te verlagen. Het abonnement werd geïntroduceerd om te voldoen aan de Digital Markets Act, maar de prijs van 10 euro per maand zorgde voor veel kritiek.
- De online winkel van OpenAI waarin ChatGPT-chatbots voor specifieke taken te vinden zijn, zit vol met chatbots die auteursrechten schenden. Daarnaast blijkt het te worden gebruikt als spammethode om betaalde diensten aan te prijzen.